Usando R para analizar y visualizar tweets de SACNAS
Esta publicación de blog explica cómo uso R para analizar los datos de Twitter para comprender mejor quién está tuiteando en las conferencias y cuán impactantes son esos tweets. Espero que encuentre útil esta explicación y que lo inspire a realizar sus propios análisis de los datos de Twitter.
Las organizaciones utilizan cada vez más los datos de Twitter como métricas para el éxito, y a veces pagan mucho dinero por este tipo de análisis. He estado usando R para analizar tweets en conferencias desde que leí la publicación de blog de François Michonneau sobre el análisis de tweets en CarpentryCon. Por lo general, hago este análisis por diversión, pero este año mi objetivo era recopilar datos que mis colegas pudieran demostrar como nuestra presencia en nuestros esfuerzos de redes sociales en SACNAS estaban teniendo un impacto cuantificable. En esta publicación de blog, explicaré cómo uso R para analizar y visualizar datos de Twitter. Lo escribí como un tutorial y he incluido todo el código que necesita para reproducir el análisis, o también puede ver el código como un script R en esta esencia. Espero que estos sean recursos valiosos que pueda modificar y reutilizar.
Paso 1. Obtener datos
rtweet es un paquete R que recopila datos de Twitter a través de las interfaces de programa de aplicación (API) REST de Twitter. La función “search_tweets()” devuelve estados de Twitter que coinciden con una consulta de búsqueda proporcionada por el usuario de los últimos 6-9 días. Hay un límite para la cantidad de estados que puede devolver en un día determinado, por lo que si necesita recopilar más de 18,000 estados, establezca “retryonratelimit = TRUE”. A veces me gusta llamar a la API varias veces al día, así que configuro el número de estados para volver a un número ligeramente superior al número que espero que se devuelva. Aquí, configuré “n = 2000” y el número total de estados devueltos fue de aproximadamente 1400 tweets y retweets.
Para este análisis, busqué todos los tuits relacionados de la conferencia SACNAS (#2019SACNAS) que estaban relacionados con Puerto Rico (#CienciaPR #CienciaBoricua #PuertoRico). En este punto, mi código se ve así:
library(rtweet)
estados <- search_tweets('2019sacnas AND CienciaPR OR CienciaBoricua OR PuertoRico', n=2000)
Esto devuelve un dataframe muy grande que tiene mucha información útil, pero estoy interesada en los tweets originales, quién está twitteando, qué están twitteando, el número de retweets y el número de favoritos. Por lo tanto, utilizo el paquete tidyverse para seleccionar las columnas y filas de interés para crear un pequeño marco de datos (que llamo “estaditos”) que es un poco más fácil de trabajar debido a su tamaño más pequeño
library(tidyverse)
estaditos <- estados %>%
filter(is_retweet == "FALSE") %>% # obtener tweets originales
select(screen_name, favorite_count,retweet_count, text) %>% # columnas de interes
arrange(desc(favorite_count)) # ordenar por los más favorecidos
head(estaditos)
## # A tibble: 6 x 4
## screen_name favorite_count retweet_count text
## <chr> <int> <int> <chr>
## 1 moefeliu 114 9 Thank you @UPRPonce RISE stude…
## 2 moefeliu 113 15 Científicas puertorriqueñas re…
## 3 yfortiss 74 0 "Landed in Hawaii for #2019SAC…
## 4 moefeliu 48 19 If you are a PhD student atten…
## 5 sociovirolo… 38 6 Inspired by Lē'ahi: We will ch…
## 6 BeccaCalisi 38 10 "Standing room only in #2019SA…
Paso 2. Calcular estadísticas resumidas
Ahora que tenemos los datos, podemos comenzar a ver algunas métricas. Yo uso nrow() para calcular el número total de tweets originales.
nrow(estaditos)
## [1] 28
Luego, uso colSums() para calcular el número total de retweets y favoritos. colSums() solo funciona en dataframes o tibbles que son numéricos, así que uso select() para seleccionar mi columna de interés.
estaditos %>%
select(retweet_count,favorite_count) %>%
colSums() # el número total de retweets y favoritos
## retweet_count favorite_count
## 113 646
Esto me dice que alrededor de 25 tweets fueron retuiteados unas 100 veces y favorecidos unas 650 veces, o que en promedio, cada tweet obtuvo 4 retweets y un poco más de 20 favoritos cada uno. Sin embargo, yo sé que algunos tweeters tienen una gran audiencia y obtienen muchos retweets, mientras que otros son nuevos en Twitter y todavía están aumentando su audiencia, por lo que utilizo group_by() y summarize() para crear un dataframe llamado “resumen” que contiene información sobre total de tweets, favoritos, retweets, favoritos promedio y retweets promedio para cada usuario de Twitter cuyos tweets coincidieron con la consulta
resumen <- estaditos %>%
group_by(screen_name) %>% # agrupar por screen name
summarize(n_tweets = n(), # cantidad de tweets totales
n_fav = sum(favorite_count), # total de favoritos
n_rt = sum(retweet_count), # total de retweets
promedio_fav = round(mean(favorite_count), digits = 1), # número promedio de favoritos
promedio_rt = round(mean(retweet_count), digits = 1)) %>% #número promedio de retweets
arrange(desc(n_fav)) # ordenar
head(resumen)
## # A tibble: 6 x 6
## screen_name n_tweets n_fav n_rt promedio_fav promedio_rt
## <chr> <int> <int> <int> <dbl> <dbl>
## 1 moefeliu 4 291 43 72.8 10.8
## 2 yfortiss 2 88 2 44 1
## 3 sociovirology 4 53 9 13.2 2.2
## 4 Renetta_Tull 4 50 7 12.5 1.8
## 5 BeccaCalisi 1 38 10 38 10
## 6 CienciaPR 2 28 10 14 5
Paso 3. Visualizar datos
Una cosa que comencé a hacer recientemente es crear primero un tema personalizado que puedo agregar a cada trama para una apariencia unificada. ¡Recomiendo hacer esto! Dependiendo de cuánto modifique su tema, puede ahorrarle o no una gran cantidad de líneas de código totales, pero asegura que todas sus figuras siempre tengan todas sus configuraciones personalizadas favoritas. Me gusta usar theme_minimal() con tamaño de fuente 8 y sin líneas de cuadrícula. (Nota: por alguna razón, los temas personalizados no funcionan con ts_plot(), por lo que ajusto manualmente el tema.)
mitema <- function(){
theme_minimal(base_size = 8) + # tema y tamaño de fuente
theme(panel.grid = element_blank()) # sin líneas de cuadrícula
}
También me gusta agregar imágenes a las figuras con magick y cowplot. Cambio entre dos métodos dependiendo de lo difícil que sea posicionar la imagen exactamente donde la quiero en la trama. Prefiero leer imágenes de URL en lugar de archivos porque esto hace que mi canal de análisis sea más fácil de reproducir y reutilizar. Tenga paciencia cuando ejecute el código para trazados con imágenes porque tardan más en cargarse.
library(magick)
library(cowplot)
img1 <- image_read("http://www.gradpost.ucsb.edu/images/default-source/default-album/sacnas.jpg?sfvrsn=1")
img2 <- image_read("https://upload.wikimedia.org/wikipedia/commons/thumb/2/28/Flag_of_Puerto_Rico.svg/1024px-Flag_of_Puerto_Rico.svg.png")
img <- image_read("https://pbs.twimg.com/media/EIPodEKX0AAdF8C?format=jpg&name=small")
rast <- grid::rasterGrob(img, interpolate = T)
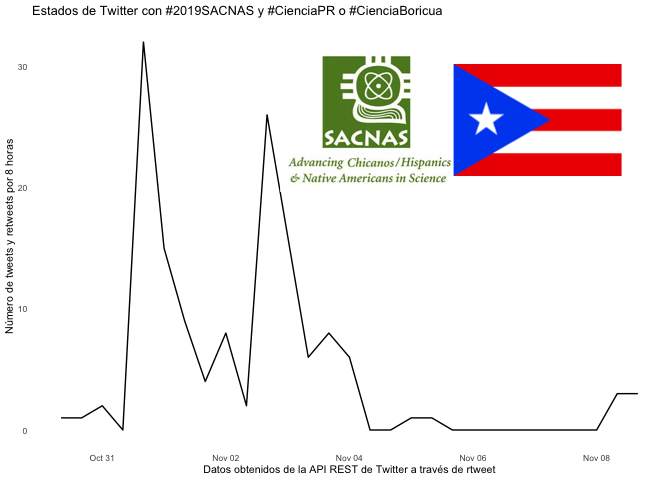
Esta primera gráfica utiliza una función del paquete rtweets llamada ts_plot() para visualizar la frecuencia de los tweets durante los últimos 6-9 días. Siempre empiezo con esta imagen porque muestra cuándo se recopilaron los datos. Esta conferencia tuvo lugar del 30 de octubre al 2 de noviembre, pero se recogieron tweets del 31 de octubre al 8 de noviembre.
tiempodetweets <- ts_plot(estados, "8 hour") +
ggplot2::labs(y = "Número de tweets y retweets por 8 horas",
x = "Datos obtenidos de la API REST de Twitter a través de rtweet",
title = "Estados de Twitter con #2019SACNAS y #CienciaPR o #CienciaBoricua") +
theme_minimal(base_size = 8) +
theme(panel.grid = element_blank())
ggdraw(tiempodetweets) +
draw_image(img1, scale = 0.3, x = 0.07, y = 0.25) +
draw_image(img2, scale = 0.25, x = 0.3, y = 0.25)

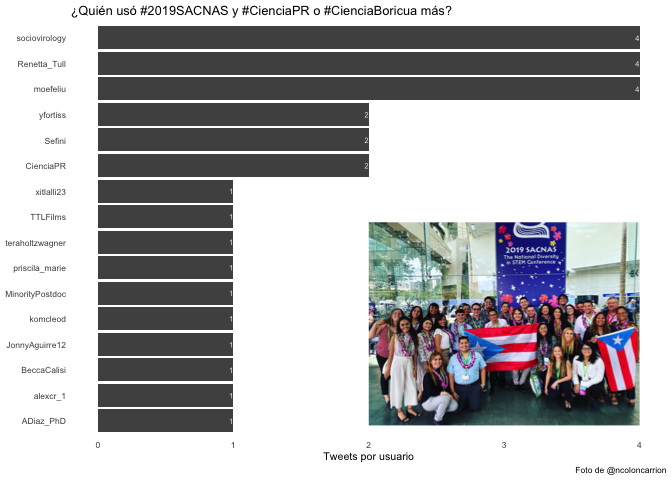
A continuación, examino quién es el que más twittea en vivo al trazar el número total de tweets por usuario. Cambio los ejes x e y para que sea más fácil leer los nombres, y reordeno el eje para que los nombres se presenten en orden descendente en lugar de orden alfabético. También filtro los datos a los 15 usuarios principales para cada una de las parcelas en lugar de mostrar a todos los usuarios para garantizar que los ejes sean siempre legibles. Uso geom_text() para etiquetar las barras con el valor. Me gusta usar los colores de la escuela si puedo, así que te animo a que juegues con los colores para combinar una affilación. Agrego un subtítulo explicativo para dar una idea de qué preguntas se pueden responder con este argumento.
resumen %>% top_n(15, n_tweets) %>%
ggplot() +
geom_bar(aes(x = reorder(screen_name, n_tweets), y = n_tweets),
stat = "identity", fill = "#505050") +
geom_text(aes(label = n_tweets, y = n_tweets, x = screen_name),
hjust=1, size = 2, color = "#E1E9E8") +
labs(x = NULL, y = "Tweets por usuario",
title = "¿Quién usó #2019SACNAS y #CienciaPR o #CienciaBoricua más?",
caption = "Foto de @ncoloncarrion") +
coord_flip() + # Cambio los ejes
mitema() + # añadir tema personalizado
annotation_custom(rast, ymin = 2, ymax = 4, xmin = -7) # añadir foto
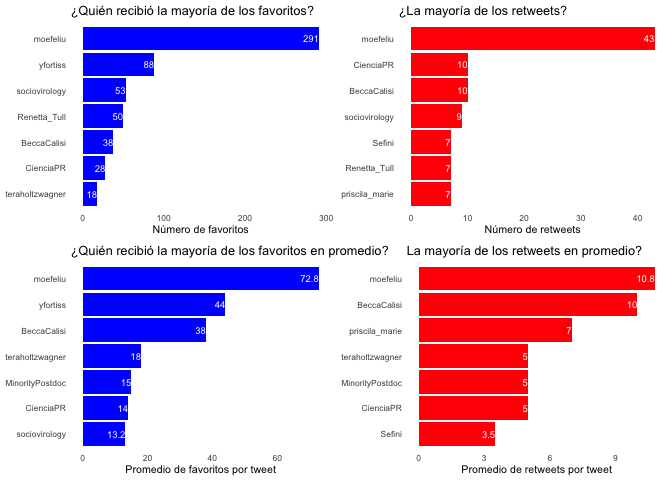
Luego, examino qué tweeters obtuvieron la mayor cantidad de favoritos totales, retweets totales, favoritos promedio y retweets promedio para todos sus tweets combinados. Uso el paquete cowplot y la función plot_grid() para colocar las dos parcelas una al lado de la otra. Cuando tienes un conjunto de datos realmente grande, me gusta la métrica “promedio” porque resalta a algunos de los usuarios que tuitearon con menos frecuencia pero tuitearon cosas que resonaron con una gran audiencia.
library(cowplot)
a <- resumen %>% top_n(7, n_fav) %>%
ggplot() +
geom_bar(aes(x = reorder(screen_name, n_fav), y = n_fav),
stat = "identity", fill = "blue") +
geom_text(aes(label = n_fav, y = n_fav, x = screen_name),
hjust=1, size = 2.5, color = "white") +
labs(x = NULL, y = "Número de favoritos", title = "¿Quién recibió la mayoría de los favoritos?") +
coord_flip() +
mitema()
b <- resumen %>% top_n(7, n_rt) %>%
ggplot() +
geom_bar(aes(x = reorder(screen_name, n_rt), y = n_rt),
stat = "identity", fill = "red") +
geom_text(aes(label = n_rt, y = n_rt, x = screen_name),
hjust=1, size = 2.5, color = "white") +
labs(x = NULL, y = "Número de retweets", title = "¿La mayoría de los retweets?") +
coord_flip() +
mitema()
c <- resumen %>% top_n(7, promedio_fav) %>%
ggplot() +
geom_bar(aes(x = reorder(screen_name, promedio_fav), y = promedio_fav),
stat = "identity", fill = "blue") +
geom_text(aes(label = promedio_fav, y = promedio_fav, x = screen_name),
hjust=1, size = 2.5, color = "white") +
labs(x = NULL, y = "Promedio de favoritos por tweet",
title = "¿Quién recibió la mayoría de los favoritos en promedio?") +
coord_flip() +
mitema()
d <- resumen %>% top_n(7, promedio_rt) %>%
ggplot() +
geom_bar(aes(x = reorder(screen_name, promedio_rt), y = promedio_rt),
stat = "identity", fill = "red") +
geom_text(aes(label = promedio_rt, y = promedio_rt, x = screen_name),
hjust=1, size = 2.5, color = "white") +
labs(x = NULL, y = "Promedio de retweets por tweet", title = "La mayoría de los retweets en promedio?") +
coord_flip() +
mitema()
plot_grid(a,b, c,d)
Paso adicional: examina los retweets para buscar alcance
En este punto de mi análisis, contacté a un grupo de líderes de la comunidad y le pregunté qué métricas adicionales debería investigar. Stefanie Butland me preguntó si podía evaluar qué retweets provenían de personas que no estaban en la conferencia. Para hacer esto, primero creé una lista de todos los identificadores de Twitter de las personas en los gráficos anteriores. Luego, creé dos marcos de datos, uno con el total de retweets (incluidos los retweets citados) y otro que excluye los tweets de la conferencia. Las columnas son un poco confusas, en mi opinión, porque “screen_name” se refiere a la persona que retuitea un tweet mientras que “retweet_screen_name”” se refiere a la persona que escribió el tweet resumen. Las filas totales en cada marco de datos son equivalentes a los retweets totales, por lo que concluí que aproximadamente el 75% de nuestros retweets fueron hechos por personas que no estuvieron en la conferencia. Creo que esta es una buena evidencia de que los tweets llegaron a una gran audiencia y tuvieron un amplio impacto.
personasenSACNAS <- resumen$screen_name
personasenSACNAS
## [1] "moefeliu" "yfortiss" "sociovirology"
## [4] "Renetta_Tull" "BeccaCalisi" "CienciaPR"
## [7] "teraholtzwagner" "MinorityPostdoc" "TTLFilms"
## [10] "priscila_marie" "komcleod" "Sefini"
## [13] "JonnyAguirre12" "ADiaz_PhD" "alexcr_1"
## [16] "xitlalli23"
retweets_total <- estados %>%
filter(is_retweet == "TRUE" | is_quote == "TRUE") %>%
select(screen_name, retweet_screen_name, retweet_count, text)
retweets_total
## # A tibble: 119 x 4
## screen_name retweet_screen_n… retweet_count text
## <chr> <chr> <int> <chr>
## 1 SK_voltage Sefini 4 "\"SACNAS: Nuestra Confer…
## 2 chelsea_newb… Sefini 4 "\"SACNAS: Nuestra Confer…
## 3 sofiamacgiron Sefini 4 "\"SACNAS: Nuestra Confer…
## 4 CienciaPR Sefini 4 "\"SACNAS: Nuestra Confer…
## 5 CienciaPR yfortiss 2 #2019SACNAS Thinking abou…
## 6 CienciaPR Sefini 4 Proud of Jaylissa Torres …
## 7 CienciaPR BeccaCalisi 10 "Standing room only in #2…
## 8 CienciaPR Sefini 3 Talking about the importa…
## 9 CienciaPR moefeliu 19 If you are a PhD student …
## 10 Sefini CienciaPR 8 Leadership doesn’t have t…
## # … with 109 more rows
retweets_sinpersonasenSACNAS <- estados %>%
filter(is_retweet == "TRUE" | is_quote == "TRUE") %>%
filter(!screen_name %in% personasenSACNAS) %>%
select(screen_name, retweet_screen_name, retweet_count, text)
retweets_sinpersonasenSACNAS
## # A tibble: 93 x 4
## screen_name retweet_screen_n… retweet_count text
## <chr> <chr> <int> <chr>
## 1 SK_voltage Sefini 4 "\"SACNAS: Nuestra Confer…
## 2 chelsea_newb… Sefini 4 "\"SACNAS: Nuestra Confer…
## 3 sofiamacgiron Sefini 4 "\"SACNAS: Nuestra Confer…
## 4 uprcayey CienciaPR 2 Hey #2019SACNAS! Today at…
## 5 vdiazochoa sociovirology 3 Parting thoughts for #201…
## 6 vdiazochoa sociovirology 6 Inspired by Lē'ahi: We wi…
## 7 PubHealthCit… Renetta_Tull 4 "@sociovirology @sacnas @…
## 8 DrLHamilton Renetta_Tull 4 "@sociovirology @sacnas @…
## 9 ctitusbrown sociovirology 3 Parting thoughts for #201…
## 10 raynamharris sociovirology 3 Parting thoughts for #201…
## # … with 83 more rows
nrow(retweets_sinpersonasenSACNAS) / nrow(retweets_total) * 100
## [1] 78.15126
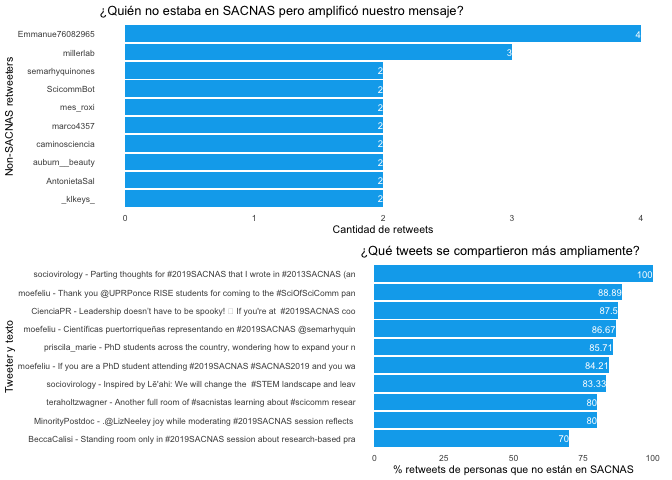
Aunque no es de mi interés en usar Twitter para comercializar o identificar personas influyentes, imagino que algunas personas sí lo están. En esta visualización final, el panel superior muestra qué Tweeters que no son de UC Davis nos retuitearon más. Creo que este es un indicador de personas que han compartido valores y podrían ser influyentes valiosos. El panel inferior muestra qué tweets llegaron a la audiencia más amplia, que podrían ser buenos tweets para promocionar si tiene el presupuesto para publicidad.
e <- retweets_sinpersonasenSACNAS %>%
group_by(screen_name) %>%
summarize(n_rt = n()) %>%
arrange(desc(n_rt)) %>%
head(10) %>%
ggplot() +
geom_bar(aes(x = reorder(screen_name, n_rt), y = n_rt),
stat = "identity", fill = "#00acee") +
geom_text(aes(label = n_rt, y = n_rt, x = screen_name),
hjust=1, size = 2.5, color = "white") +
labs(x = "Non-SACNAS retweeters", y = "Cantidad de retweets",
title = "¿Quién no estaba en SACNAS pero amplificó nuestro mensaje?") +
coord_flip() +
mitema()
f <- retweets_sinpersonasenSACNAS %>%
group_by(retweet_count,retweet_screen_name, text) %>%
summarize(n_rt = n()) %>%
arrange(desc(n_rt)) %>%
mutate(quien.texto = paste(retweet_screen_name, text, sep = " - "),
texto.corto = substr(quien.texto, start=1, stop=80),
porcentaje = round((n_rt / retweet_count *100),2)) %>%
head(10) %>%
ggplot() +
geom_bar(aes(x = reorder(texto.corto, porcentaje), y = porcentaje),
stat = "identity", fill = "#00acee") +
geom_text(aes(label = porcentaje, y = porcentaje, x = texto.corto),
hjust=1, size = 2.5, color = "white") +
labs(x = "Tweeter y texto", y = "% retweets de personas que no están en SACNAS",
title = "¿Qué tweets se compartieron más ampliamente?") +
coord_flip() +
mitema()
plot_grid(e,f, nrow = 2)
Conclusión
Entonces, así es como uso R para analizar los datos de Twitter para comprender mejor quién está twitteando y cuán impactantes son esos tweets. Espero que haya encontrado útil esta explicación y que lo inspire a realizar su propio análisis #rstats de los datos de Twitter. Siéntase libre de agregar sugerencias o comentarios en los comentarios a continuación.
Expresiones de gratitud
Esta publicación de blog se inspiró en una conversación sobre análisis de Twitter en el aeropuerto de Honolulu con Yaihara Fortis, Laurel Allen y Lauren Esposito. Quiero agradecer a mi asesora, Rebecca Calisi Rodriguez, por brindarme apoyo financiero con entusiasmo para que yo asistiera a SACNAS y Tim McConville, Alexandra Colón-Rodríguez, Jen Guerra y Ana Molina Gil por ser increíbles compañeros de equipo mientras trabajábamos en un documental sobre la conferencia. Estoy agradecido de que Renetta Tull reunió a 40 miembros de la facultad, estudiantes, postdoctorados y personal de todo el campus de UC Davis para trabajar juntos para promover la diversidad en STEM a través de Twitter. Agradezco a Victoria Farrar por probar el código R, a Stefanie Butland por sugerir nuevos análisis, y a Pachá por feedback sobre la traducción. Gracias por leer :)